Les promesses de Common Lisp (et les limitations de Python)
Table of Contents
Ces derniers temps je me suis heurté aux limitations de Python (le language et la "plateforme") et je suis en passe de trouver les solutions dans Common Lisp. Vous allez voir, les possibilités sont accrues. Néanmoins, ce n'est pas sans quelques frustrations et je ne recommande rien encore: je n'ai pas encore pu tout tester, et la documentation doit s'améliorer (heureusement, c'est en cours).
D'abord quelques réponses aux premières objections et quelques bons liens:
- vous pouvez utiliser Emacs, Vim, Atom (atom-slime) ou LispWorks (éditeur propriétaire),
- qui fait aujourd'hui du CL ? (en effet, pas grand monde ne blogue à ce
propos):
- déjà, un éventail de softs à succès dans l'industrie: http://lisp-lang.org/success/
- c'est un language utilisé dans l'IA, à ce titre enseigné dans des universités
- le métro londonien et d'autres capitales (pdf)
- pgloader (ré-écrit de Python en CL pour, entre autres, un gain de performances d'un facteur 30 -je répète, trente ;)),
- Framasoft pour les Framanotes (Turtl, backend en CL et front en JS),
- la recherche en bio-informatique (Clasp, LLVM et C++)
- les sponsors de Quicklisp (le gestionnaire de paquets): Rigetti, "on a mission to build the world's most powerful computer",
- les sponsors de la conférence ELS,
- l'entreprise FranzInc qui vend son implémentation AllegroCL et des produits en CL, notamment Allegrograph, sa solution de graphs sémantiques,
- …
Les bons liens pour débuter:
- http://lisp-lang.org/
- https://github.com/CodyReichert/awesome-cl
- https://lispcookbook.github.io/cl-cookbook/
- http://cl21.org/ (on en reparlera à l'occasion)
Ok, donc, n'êtes-vous pas frustré-es comme moi, en Python, par les choses suivantes:
- manque de paradigme fonctionnel (malgré Coconut et autres, qui ne comblent pas les limitations suivantes),
- Python 2 VS Python 3,
- manque de typage, malgré my-py, encore une surcouche,
- Python est lent, on s'en rend compte même pour des choses peu complexes,
- développement pas idéal pour moi:
- j'en ai marre qu'au moindre changement de source tout le serveur de dév doive redémarrer,
- je peux difficilement lancer un test unitaire précis (sauf par un long chemin manuel sur la ligne de commande ou une config très personnelle d'Emacs),
- j'en ai marre de devoir redémarrer toute mon appli pour lancer un ou des tests,
- et ainsi de perdre mes essais dans ipython,
- de même de devoir tout redémarrer pour prendre en compte les changements de code dans ipython,
- quasi-impossibilité de fournir un exécutable pour une application, sauf peut être pour Windows, et encore moins pour des applis web. J'ai essayé Nuitka, Pyinstaller, Electron pour Python… tous des hacks inaboutis qui demandent l'inclusion manuelle de plein de fichiers, et impossible de livrer des webapps (oh, peut être Briefcase ?).
- les applis webs justement: j'aimerais avoir un et un seul language pour toute mon appli… et voir si ça marche bien (sinon, back en CL et front en JS (ou ClojureScript) est évidemment possible, certains font ça actuellement). Aujourd'hui on doit forcément passer par un framework JS, du html (ou pugjs) et un language de template, ce qui fait de nouvelles choses à apprendre, à configurer, à débugguer, et au final donne un truc moche et illisible: les templates jinja d'une vraie appli sont plein de tags spéciaux, de factorisation du html avec les macros jinja, d'héritage pugjs, de tags pour laisser la place à Angularjs ou Vue.js,… Nagare ?
déploiement de projets web: encore une nouvelle gageure pour laquelle il n'existe pas de manière simple et "built-in": on doit se fabricoter des règles Fabric, Ansible, configurer les superviseurs, serveurs web,…
Or oui, Common Lisp résoud (apparemment) tout cela.
Mais pas sans contreparties: documentation pourrie (sauf dans les livres, ce qui n'est pas rien, et en amélioration sur quelques sites rares), une entrée en matière difficile et frustrante (moins maintenant avec le Cookbook, espérons) et certains projets encore trop confidentiels.
1 Paradigme fonctionnel
Common Lisp est multi-paradigme, ce qui nous donne des macros loop
pas très "lispy", mais on peut quand même faire du fonctionnel avec
des map, closures, pattern matching (librairie), pipes (threading
macro, librairie), …
Ce qui était frustrant pour moi, débutant impatient, est le manque de
généricité, c'est à dire le nombre de fonctions différentes qui
réalisent pourtant la "même" action mais sur un type différent: en
python les opérateurs marchent sur toute sorte de structures de
données (+, len, l'accès [],…), mais en CL ce
sera des fonctions différentes… en effet, le système objet (CLOS, CL
Object System) a été développé après coup. C'est donc possible
(méthodes génériques) mais peu usité. La librairie cl21, "CL pour le
21e siècle", redéfinit pas mal de fonctions de manière générique.
CL21 ne fait pas l'unanimité, forcément, mais marche très bien pour
moi :)
2 Typage
CL n'est ni typé statiquement ni totalement dynamique comme Python. Il calcule bien plus d'inférences de type et nous décèle plus d'erreurs et de warnings à la compilation que Python (… forcément ?).
Tous les détails sont dans (eheh surprise): le papier de recherche du compilateur Python pour Common Lisp, développé à l'Université Carnegie Mellon en 1992: https://www.researchgate.net/publication/221252239_Python_compiler_for_CMU_common_Lisp où ici "Python" n'a rien à voir avec notre language, c'est le nom de ce compilateur :)
En pratique, on obtient ces erreurs et warnings à chaque fois qu'on
compile une fonction, c'est à dire souvent (dans Slime, c'est le
réflexe C-c C-c).
On peut également désassemble le code d'une fonction pour vérifier qu'on l'a optimisée et de la bonne manière.
Je vous renvoie vers http://blog.30dor.com/2014/03/21/performance-and-types-in-lisp/ et au livre "Common Lisp Recipes" (paru en 2015, étonnant mais vrai ;) Jetez un œil ici puis achetez-le !).
Petit exemple. Si on a:
(defun foo (x y) (declare (type integer x y)) (logxor x y))
foo est reconnu comme une fonction qui prend 2 integers en
argument:
(describe 'foo) ⋮ Derived type: (FUNCTION (INTEGER INTEGER) (VALUES INTEGER &OPTIONAL))
Mais un integer c'est assez général: ('scusez je vous commente pas l'assembleur, c'est acquis)
(disassemble 'foo) ; disassembly for FOO ; 02B8BC8F: 4883EC18 SUB RSP, 24 ; no-arg-parsing entry point ; 93: 48896C2408 MOV [RSP+8], RBP ; 98: 488D6C2408 LEA RBP, [RSP+8] ; 9D: B904000000 MOV ECX, 4 ; A2: 488B0425980B1020 MOV RAX, [#x20100B98] ; AA: FFD0 CALL RAX ; AC: 488BE5 MOV RSP, RBP ; AF: F8 CLC ; B0: 5D POP RBP ; B1: C3 RET
On déclare un integer non signé de 32 bits:
(defun foo (x y) (declare (type (unsigned-byte 32) x y)) (logxor x y)) FOO (describe 'foo) […] ; Derived type: (FUNCTION ((UNSIGNED-BYTE 32) (UNSIGNED-BYTE 32)) ; (VALUES (UNSIGNED-BYTE 32) &OPTIONAL))
et l'assembleur:
(disassemble 'foo) ; disassembly for FOO ; 02C9EB0F: 4831FA XOR RDX, RDI ; no-arg-parsing entry point ; 12: 488BE5 MOV RSP, RBP ; 15: F8 CLC ; 16: 5D POP RBP ; 17: C3 RET
Ce qui va s'exécuter bien plus vite.
Bonus:
- doc officielle: https://common-lisp.net/project/cmucl/doc/cmu-user/compiler-hint.html
- "Strong static type checking for Functional Common Lisp": http://www.cs.utexas.edu/users/boyer/ftp/diss/akers.pdf
3 Performance
Le CL compile en code machine. Avec quelques déclarations de type on peut obtenir du code aussi ou plus performant que du code C.
4 Environnement de développement
J'utilise Emacs et Slime (il existe Sly et des plugins pour Vim et
Atom) et le développement est très interactif. Dans le code source,
on peut recompiler une fonction à la fois, lancer un test unitaire
à la fois, travailler dans le REPL, recompiler une fonction,
l'utiliser de suite, sans perdre les variables et données du REPL,
enregistrer l'état courant de l'image (afin par exemple de garder
des variables qui auraient pris du temps à être calculées), on
tombe dans un débuggueur interactif lors d'une exception, on peut
(il paraît) y modifier des variables ou fonctions et reprendre
l'exécution d'où elle s'est arrêtée (système de conditions et
restarts), on peut inspecter la structure de n'importe quoi au
clavier ou à la souris, on débuggue un programme avec trace,
step et cie, on débuggue une instance à
distance, y
compris si elle est dans l'espace,…
Inspecter la source d'un symbole n'a jamais été aussi facile (M-.
sous Slime), sachant que je ne me suis jamais installé ça sous
Emacs, à la fois par manque de volonté, d'informations et de
facilité, alors que je développe des extensions en Elisp… De même,
inclure dans son environnement la version en développement d'une
librairie est super facile, et donc de contribuer à des trucs dont
on n'aurait pas eu l'idée en Python, car il suffit de la mettre
dans ~/quicklisp/local-projects/ et elle est chargée en priorité
par Quicklisp (mais on peut aussi utiliser l'équivalent des
virtualenvs avec Qlot). D'ailleurs, ce gestionnaire de paquets est
encore différent de ce qu'on connaît par ailleurs, notamment par le
fait qu'il se charge de tester que toutes les librairies
disponibles ne rentrent pas en conflit entre elles.
C'est un environnement différent, qu'il faut se laisser le temps d'apprivoiser.
5 Fournir un exécutable ou une image
C'est une fonctionnalité de base des implémentations CL. J'ai très facilement essayé ça, c'est une commande à lancer, même pour des applis web (qui contiennent leur serveur web).
Un exécutable standalone pèsera quelques Mo. On peut aussi partager des scripts avec Roswell.
De plus, ECL (Embeddable Common Lisp) compile en C et peut fournir un simple exécutable, pour toutes plateformes, y compris Android. ABCL est pour la JVM, et il y en a d'autres.
6 Développement web
Le serveur par défaut est Hunchentoot (un mix de serveur et de framework), Clack est une abstraction (WSGI chez Python) pour pouvoir changer de serveur (Hunchentoot, Woo (basé sur libev, de Nodejs), Wookie (asynchrone),…).
Caveman et Lucerne sont des frameworks avec une approche traditionnelle.
On peut utiliser des templates à la Django avec Djula ou du lisp avec Spinneret, cl-who ou d'autres.
Parenscript est LE compilateur de CL vers Javascript.
Ansi, on peut très bien développer un backend en CL et le front en ce qu'on veut. C'est l'approche de Turtl, de Potato (similaire à Slack, front en ClojureScript), de pgchart (oh, c'est une appli web "standalone"),…
Est-ce que tout ce monde marche ensemble ? En partie oui, dans le vénérable Weblocks. Son site actuel est une honte, mais je le mentionne car il est toujours maintenu et un gars est en train de le revitaliser dans sa branche de développement. Il a créé une nouvelle doc sur un nouveau site (http://40ants.com/weblocks/) et s'est lancé depuis quelques mois dans une refonte du code. Son tutoriel (le fameux todomvc) marche, et est facile et parfaitement lisible.
Enfin, avec un déploiement facile, ce pourrait être la panacée.
7 Déploiement
On a déjà la création d'exécutables "standalones" et d'images.
On a des outils pour faciliter encore le processus (deploy). Certains frameworks permettent d'héberger plusieurs sites web dans une image (Weblocks, Radiance, Hunchentoot ?). Weblocks ou des librairies gèrent les dépendances JS pour nous.
On peut se connecter à une image qui tourne à distance.
Le site de Caveman donne un moyen pour du déploiement "à chaud" (hot swaping, déploiement sans interruption de service).
Ceramic nous permet de mettre des web apps sur Electron.
J'ai déjà eu besoin de pouvoir faire ça en Python. Ça existe en CL, et je me demande bien s'il existe une plateforme aussi complète.
8 En guise de conclusion
Je soutiens que la plaie de l'écosystème CL est son manque de documentation, de documentation attractive et plus globalement de communication. Heureusement, ça bouge de ce côté-là (lisp-lang.org, le Cookbook, refonte de la doc de référence,…).
Le language en lui-même contient des inconsistances et trucs un peu vieillots, mais ce peut être corrigé par des librairies (cl21 ou de plus spécialisées moins intrusives) (et… on s'habitue). Mais étant donné toutes les fonctionnalités du language et de la plateforme, il nous paraît carrément valoir le coup de ne pas se précipiter et de nous familiariser avec ce monde, un peu alien.
On reviendra, peut être, pour comparer plus spécifiquement les écosystèmes CL et Python. En attendant:
sudo apt-get install sbcl
ou voyez Portacle, environnement de développement portable et multiplateforme (Emacs + SBCL + Quicklisp + Slime + Git).
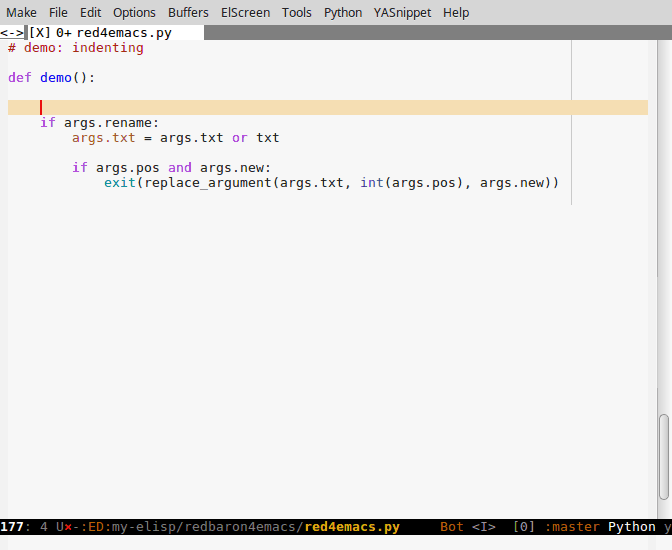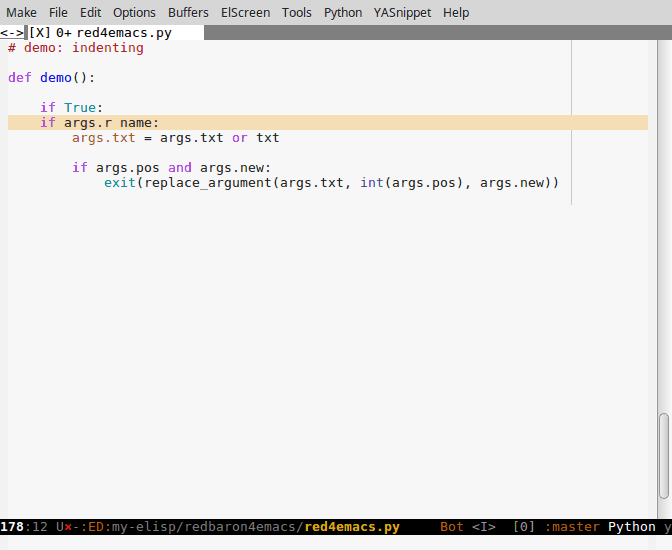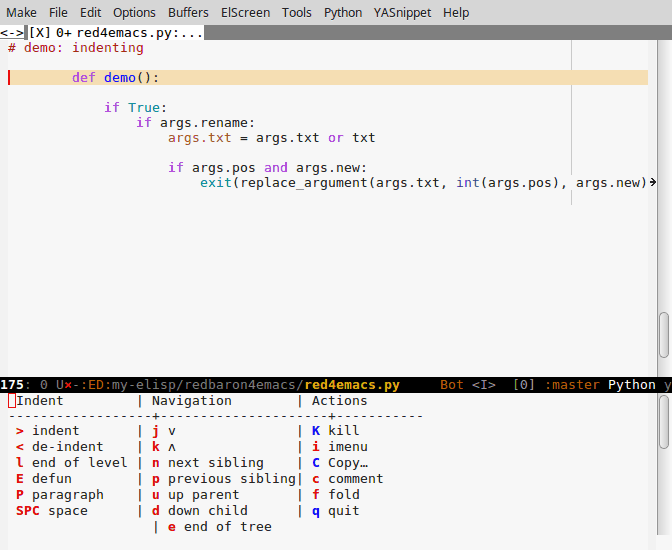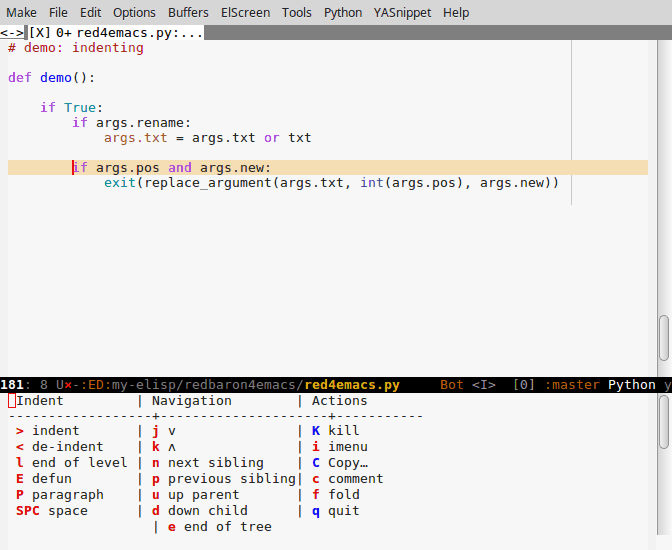
Navigation dans un grand fichier yaml, indentation de code par blocs d'indentation: indent-tools pour Emacs
Indent-tools est un nouveau paquet Emacs qui fonctionne par niveaux d'indentation, ce qui est parfait pour du yaml, python, jade ou autre:
- navigation par blocs: prochain bloc du même niveau, niveau parent, etc
- indentation
- commenter, effacer, plier le bloc courant, le paragraphe, etc
On peut utiliser un mode "mineur", des raccourcis clavier pour chaque action, ou bien invoquer une hydre à plusieurs têtes, qui non seulement affiche un petit menu des actions possibles mais aussi permet d'appliquer plusieurs actions d'affilée avec une seule touche.
Navigation:

Indentation:
Pour l'installer, il faut avoir configuré le dépôt Melpa et utiliser le gestionnaire de paquets d'Emacs, package.el:
Alt-x package-install RET indent-tools RET
(un rafraichissement avec M-x package-refresh-contents peut être
utile).
C'est la première version, il y aura des limitations voire quelques bugs, n'hésitez pas les remonter sur le dépôt Gitlab.
Installer lxc et lxd sur Debian Jessie
LXC, pour "linux containers", est un système de virtualisation similaire à Docker (Docker était initialement basé sur LXC), et lxd est une sorte de superviseur, un outil de plus haut niveau pour LXC. Je vous laisse lire la doc, mais c'est génial. Comparé à Docker, lxc/lxd:
- est plus orienté "tout dans une VM". LXD fait tourner une distro, tout ce qu'on fait dans une VM ou sur une vrai machine, on peut le faire dans une image LXD. À l'inverset les images Docker sont censées être plus petites, dédiées à une tâche et sont éphémères. Voir Why LXD ?
- peut se souvenir de l'état de la machine virtuelle, des données enregistrées
- possède une api go et python
- permet de migrer des images, en live, d'un server à un autre
- possède bien moins de doc et les retours, positifs ou négatifs, sont rares.
Étant plus que prudent sur Docker, je m'intéresse de près à lxd (je n'ai encore rien mis en prod, pas d'avis sur ça).
Update: on peut maintenant installer LXD dans Debian avec un Snap. Un paquet Debian est aussi en cours.
LXD est développé par Canonical. La dernière version est dispo sur Ubuntu 16.04. Sur Debian, on a la v1 de LXC, il n'y a pas encore de paquet pour LXD, lequel nécessite lxc v2 qui est présent dans les backports de Jessie. On va compiler LXD, ce qui est rapide.
On commence par installer les dépôts backport:
echo "deb http://ftp2.fr.debian.org/debian/ jessie-backports main" >> /etc/apt/sources.list.d/additional-repositories.list
On installe les dépendances:
sudo apt-get -t jessie-backports install lxc-dev lxc golang-go squashfs-tools xz-utils
On clone le projet lxd:
git clone git://github.com/lxc/lxd cd lxd
À partir de là il suffit de suivre le README. Pour info, il nous suffit de :
mkdir -p ~/go export GOPATH=~/go go get github.com/lxc/lxd cd $GOPATH/src/github.com/lxc/lxd make
et voilà.
Maintenant, amusons-nous: https://linuxcontainers.org/lxd/getting-started-cli/
Nous pouvons télécharger ou créer des images, en prendre des snapshots, avoir la main sur un shell, inclure des fichiers du système hôte, accéder au réseau, configurer des profils, choisir son système de fichiers, interagir avec un démon LXD à distance, utiliser son API rest, … Facile. Mais qui a des retours pour une mise en prod, un déploiement d'application Python/Django ?
GNU Guix dans un environnement de supercalculateurs
Table of Contents
- 1. Comment perdre du temps à compiler et à déployer des logiciels
- 2. La compilation
- 3. Les dépendances système
- 4. Les conflits de versions
- 5. Interopérabilité
- 6. La gestion de paquets fonctionnelle avec GNU Guix
- 7. Isolé, mais partagé
- 8. Liberté de l'utilisateur
- 9. Partager le store entre stations de travail
- 10. Guix en tant que plateforme pour logiciels scientifiques
(Ce billet est la traduction (à 90% complète et francisée) d'un article de Rekado paru en avril 2015.)
Je travaille en tant qu'administrateur système dans un institut de recherche dans un environnement informatique très diversifié. Nous avons deux supercalculateurs en clusters (un sur CentOS et l'autre sur Ubuntu) avec environs 100 nœuds chacuns et des douzaines de postes de travail sous GNU/Linux. Une de mes tâches est de m'assurer que les utilisateurs peuvent faire tourner leurs programmes de bio-informatique, à la fois sur leurs postes de travail et sur les clusters. Seuls quelques outils et librairies de cette discipline sont assez populaires pour avoir été packagés pour CentOS ou Ubuntu, donc généralement on doit construire les applications (avec toutes leurs dépendances) sur les plateformes cibles.
1 Comment perdre du temps à compiler et à déployer des logiciels
En théorie, compiler un logiciel n'est pas très difficile. Une fois que les fichiers d'en-tête ont été installés sur la machine hôte, la compilation ne consiste plus qu'à configurer le build avec un script de configuration et de lancer GNU make avec les flags appropriés (c'est une hypothèse régulièrement violée par les programmes de bio-informatique, mais laissons ça de côté pour le moment).
Néanmoins, il y a des problèmes pratiques qui deviennent clairement embêtants dans un environnement partagé avec un grand nombre d'utilisateurs.
2 La compilation
Compiler directement sur la machine cible n'est une option que dans les cas les plus simples. Quand le système de build ou les dépendances sont plus compliqués, les administrateurs système sont tentés de ne lancer les grosses opérations qu'une seule fois. La plupart du monde s'accorderait à dire que les gestionnaires de paquets sont une grande avancée par rapport à la compilation: les étapes de build sont formalisées dans des sortes de recettes qui peuvent être exécutées par des outils de build de façon reproductible. Pour mettre à jour un paquet on modifie seulement sa recette. Les gestionnaires de paquets sont une bonne chose.
3 Les dépendances système
Les programmes non triviaux qui ont été buildés et liés dynamiquement sur une machine avec un ensemble de librairies et de fichiers d'en-tête à une version donnée ne peuvent vraiment marcher que sur un système qui aura les mêmes libraires dans les mêmes versions. Nos gestionnaires de paquets habituels permettent aux mainteneurs de spécifier des plages de versions, mais les binaires produits sur la machine de build ne vont marcher que sous les contraintes imposées au moment du build. Pour faire tourner un paquet à la fois sous, mettons, CentOS 6.5 et CentOS 7.1, il doit avoir été construit dans les deux environnements et on doit récupérer un binaire pour chaque plateforme.
Il y a des moyens pour émuler un environnement de build différent (par
exemple mockbuild sous Fedora), mais on ne peut ignorer le fait que
des programmes liés dynamiquement construits pour une sorte de système
ne vont marcher que sur cette sorte de système. On peut changer au
runtime les librairies qui vont être dynamiquement chargées, mais
c'est un hack qui remet un problème des mainteneurs aux
utilisateurs. Les programmes avec LD_LIBRARY_PATH ne sont pas une
solution, tout comme ne le sont pas les liens statiques, l'équivalent
de copier des bouts de librairies au moment du build.
4 Les conflits de versions
Les bibliothèques logicielles ou les applications qui sont pré-installées ou pré-packagées dans un système ne le sont peut être pas dans la version dont l'utilisateur dit avoir besoin. Prenons un utilisateur qui souhaite la dernière version de GCC pour compiler du code qui utilise des fonctionnalités arrivées dans C++11 (par exemple, les fonctions anonymes). Le support complet de C++11 est arrivé dans GCC 4.8.1, pourtant sur CentOS 6.5 seule la version 4.4.7 était disponible dans les dépôts. Peut être que l'administrateur système ne peut pas mettre à jour GCC globalement. Ou peut être que d'autres utilisateurs sur le même système partagé ont besoin de la version 4.4.7 (pour la compatibilité de bugs par exemple). Il n'y a pas de moyen facile pour satisfaire tout le monde, donc un admin sys pourrait abandonner et laisser les utilisateurs construire leurs propres paquets dans leur répertoire personnel, au lieu de résoudre le problème.
Par contre, compiler GCC est une tâche énorme pour un utilisateur, ils
ne devraient vraiment pas avoir à le faire. On a déjà dit que les
gestionnaires de paquets sont une bonne chose. Pourquoi leur interdire
ces bénéfices ? Les techniques de gestion de paquets traditionnelles
ne sont pas faites pour installer plusieurs versions d'une même
application. RPM, par exemple, permet d'utiliser une base de donnée de
paquets locale, mais yum ne marche pas avec plusieurs sources. […]
5 Interopérabilité
Un admin sys qui décide de packager une application en RPM […] et de maintenir un dépôt logiciel se retrouve le bec dans l'eau quand un utilisateur lui demande d'installer cette application sur un poste Ubuntu. Il y a bien quelques moyens pour transformen un RPM en DEB, avec des degrés divers de réussite, mais ça paraît dingue de devoir tout constamment convertir ou reconstruire quand le logiciel, ses dépendances et son mode de déploiement n'ont pas changés.
Et que se passe-t-il lorsqu'un nouveau venu de Slackware pointe son nez ? Ou quelqu'un d'Arch Linux ? Bien sûr, en tant qu'admin sys vous pourriez refuser de prendre en charge autre chose que CentOS 7.1, au diable ces utilisateurs. On dirait bien que c'est cette politique qui prévaut chez les admin sys, pour des raisons de facilité et/ou pratiques, mais je considère que ça n'aide pas et que c'est même en quelque sorte oppressant.
6 La gestion de paquets fonctionnelle avec GNU Guix
Heureusement, je ne suis pas le seul à considérer la gestion de paquets traditionnelle inapte à un certain nombre d'usages. Plusieurs projets ont pour but d'améliorer et de simplifier le déploiement et la gestion de logiciels, notamment un sur lequel je vais me pencher à la suite de cet article. En tant qu'amateur de programmation fonctionnelle, du language Scheme et de logiciel libre, j'ai été très intrigué par ma découverte de GNU Guix, un gestionnaire de paquets au paradigme fonctionnel, écrit en Guile Scheme, le language d'extension du système GNU.
En programmation fonctionnelle pure, une fonction produit toujours la même sortie lorsqu'elle est appellée avec les mêmes variables en entrée. Ça permet des optimisations intéressantes, mais surtout ça rend possible et dans certains cas facile de réfléchir au comportement d'une fonction. Elle ne dépend pas de variables globales, elle n'a pas d'effets de bord, et sa valeur de sortie peut être mise en cache étant donné qu'il est certain qu'elle ne change pas (avec la même entrée).
La gestion de paquets "fonctionnelle" introduit ce concept dans la
construction et le déploiement de logiciels. L'état global dans un
système équivaut à une installation système d'un paquet, d'une
bibliothèque ou d'un fichier d'en-tête. Les effets de bord sont les
changements dans l'environnement du système ou dans certains
répertoires tels que /usr/bin. Refuser un état global revient à
rejeter la hiérarchie habituelle du système de fichiers pour le
déploiement et d'utiliser un chroot minimal pour construire le
logiciel. L'introduction du manuel de Guix décrit leur approche comme
suit:
Le terme "fontionnel" renvoie à un concept spécifique de management de paquets. Dans Guix, le build et l'installation du paquet sont vus comme une fonction, au sens mathématique du terme. Cette fonction prend des arguments en entrée, comme des scripts de build, un compilateur, des bibliothèques, et retourne un paquet installé. En tant que fonction pure, son résultat de sortie ne dépend que de ses entrées. Par exemple, elle ne peut pas se référer à des programmes ou à des scripts qui n'aient pas été explicitement donnés en paramètres. Une fonction de build produit toujours le même résultat avec un même ensemble d'entrées. Elle ne peut en aucun cas altérer l'environnement du système, par exemple elle ne peut pas créer, modifier ou supprimer des fichiers en dehors de son répertoire d'installation. Ceci est possible en faisant tourner les processus de build dans des environnement isolés (ou "conteneurs"), dans lesquels seuls leurs entrées explicites sont visibles.
Le résultat de ces fonctions est mis en cache dans le système de fichiers, dans un répertoire spécial appelé "le magasin" (the store). Chaque paquet est installé dans son propre répertoire, dans le store (par défaut "/gnu/store"). Le nom du répertoire contient un hash de toutes les entrées du paquet, donc changer un paramètre d'entrée crée un autre répertoire.
7 Isolé, mais partagé
Remarquez que les sorties des paquets sont toujours liées dynamiquement. Les bibliothèques sont référencées dans les binaires avec leur chemin de store en entier (avec runpath). Ces résultats de fonctions, les paquets, ne sont pas des répertoires monolithiques et auto-contenants comme on peut en trouver sous MacOS.
Chaque paquet construit est mis en cache dans le store, lequel est
partagé par tous les utilisateurs du système. Par contre, ce qu'il y a
dans le store n'a par défaut pas d'influence sur l'environnement des
utilisateurs, aucun fichier ne vient polluer /usr/bin ou
/usr/lib/. Chaque changement est restreint à /gnu/store.
Guix propose par conséquent des profils d'utilisateur pour mapper l'environnement d'un utilisateur à ce qu'il y a dans le store, lequel servant de cache empêche de compiler deux fois la même chose. Un profil n'est rien de plus qu'une "forêt" de liens symboliques vers des éléments du store. En ajoutant une autre couche de liens symboliques, Guix permet aux utilisateurs de passer simplement d'une version de leur profil à une précédente, permettant de remonter dans le temps.
Chaque configuration d'utilisateur est complètement isolée des autres, ce qui permet donc à différents utilisateurs d'avoir une version différente de GCC. Mieux, un simple utilisateur pourrait avoir plusieurs profils avec chacun une version de GCC et passer de l'un à l'autre.
Guix prend le management de paquets fonctionnel au sérieux, donc à part le noyau et le hardware de la machine il n'y a pas de dépendances à des "variables globales" (des bibliothèques ou headers du système). Ça veut aussi dire que le Guix store est rempli avec l'arbre entier des dépendances, jusqu'aux headers du kernel et aux bibliothèques C. Par conséquent, les programmes d'un Guix store peuvent tourner sur des distributions GNU/Linux différentes; un Guix store partagé me permet d'utiliser les mêmes logiciels sur un poste de travail sous Fedora et sur des clusters Ubuntu et CentOS 6.5.
Cela veut dire que le programme ne doit être packagé qu'une seule fois. Et puisque les recettes de packaging sont écrites dans un langage très déclaratif construit sur Scheme, le packaging est étonnament simple (et dans ce cas c'est une joie de travailler avec Scheme).
8 Liberté de l'utilisateur
Guix libère les utilisateurs des décisions de déploiement de leurs admin sys en leur donnant le pouvoir de construire leurs logiciels dans le store, un répertoire isolé du reste du système, en utilisant des recettes simples. Les administrateurs ont seulement besoin de configurer et de lancer le démon Guix, la pièce centrale tournant en root. Ce démon écoute les requêtes émanant de l'outil Guix en ligne de commande, qui n'a pas besoin de permissions root. Ce dernier permet aux utilisateurs de gérer leurs profils, de passer d'un génération à l'autre, de construire et d'installer des paquets via le démon. Celui-là gère le store, évalue les expressions de build et met les résultats en cache, puis met à jour la forêt de liens symboliques pour mettre à jour le profil utilisateur.
Les utilisateurs sont enfin libres de gérer leurs logiciels comme ils le souhaitent, avec un degré de précison qu'ils ne pouvaient atteindre qu'avec des compilations manuelles.
9 Partager le store entre stations de travail
Guix n'est pas voué à être utilisé de manière centralisée. Le démon est censé tourner sur chaque système en root et écouter les requêtes RPC de ses utilisateurs locaux. Dans un environnement de clusters et postes de travail cette approche demande un certain effort pour être efficace et sécurisée.

À l'inverse nous avons choisi de faire tourner le démon dans un unique serveur dédié, qui écrit les profils utilisateurs et le store sur une partition en NFS. Les nœuds du cluster et les postes de travail la montent en lecture seule. Du coup les utilisateurs perdent le confort de modifier leurs profils directement sur leur poste de travail ou sur les nœuls du cluster (parce qu'ils n'ont pas d'installation locale ni du client Guix ni du démon, et parce qu'ils n'ont pas accès en écriture), mais en contrepartie leur profils sont accessibles de n'importe où. Ils n'ont qu'à se connecter au serveur Guix, où ils peuvent installer ce qu'ils veulent ou revenir à un point antérieur de leur configuration. (donc je trouve que Guix gagnerait à ce qu'on puisse lancer des commandes RPC en ssh, de manière à ce qu'on ne soit plus obligés de se connecter au serveur explicitement).
10 Guix en tant que plateforme pour logiciels scientifiques
Depuis l'hiver 2014 j'ai commencé à packager des logiciels pour GNU Guix, qui a donc pendant ce temps accumulé une bonne part de logiciels classique ou obscures de bioinformatique. Une liste de paquets disponibles avec Guix, mise à jour tous les jours, est disponible ici. Nous avons aussi des modules Python pour l'informatique scientifique, ainsi que des languages de programmation tels que R et Julia.
Je trouve que Guix est une très bonne plateforme pour informatique
scientifique dans un environnement hétérogène. Le projet suit les
lignes directrices d'un système d'exploitation libre (Free System
Distribution Guidelines) […]. Pour les logiciels qui imposent plus de
restrictions d'usage ou de distribution (comme quand est utilisée la
licence Artistic licence au lieu de la nouvelle Clarified Artistic
licence, ou quand l'usage commercial est prohibé par la licence), Guix
permet d'utiliser des modules en-dehors de l'installation de base en
utilisant la variable GUIX_PACKAGE_PATH. Et comme les paquets sont
de simples variables Scheme dans des modules Scheme, il est trivial de
rajouter des paquets à la distribution en utilisant cette variable.
Si vous souhaitez en apprendre plus sur GNU Guix je vous recommande de regarder l'excellente page du projet. N'hésitez pas à me contacter si vous souhaitez en apprendre plus sur l'empaquètement de logiciel scientifique pour Guix. Ce n'est pas dur et nous pouvons tous bénéficier à joindre nos forces pour adopter cette plateforme utilisable, fiable, hackable et libératrice pour de l'informatique scientifique faite de logiciels libres.
La communauté Guix est très sympathique, aidante et réactive. Venez donc visiter le canal IRC #guix sur Freenode, où vous me trouverez sous le pseudo "rekado".
Témoignage: passer de Vim et SublimeText à Emacs, avec la configuration Spacemacs
Un témoignage paru sur reddit…
En tant qu'utilisateur de vim et sublime dans le monde académique (je fais un peu de statistiques, un peu de développement, beaucoup de latex), j'ai toujours voulu quelque chose de mieux. Vim permet la modification rapide de fichiers distants, ce qui permet d'abattre du travail d'admin sys. Mais récemment je me suis mis au développement web et à Python pour le traitement de données, donc inévitablement j'ai senti la douleur d'utiliser vim comme un IDE incomplet pour travailler efficacement. Sublime m'a plutôt bien servi, il est rapide, intuitif, a un très bon support de latex avec le plugin latextools et il a des fonctionnalités d'IDE pour le html, css, js et python (on peut être productif dès son installation). En plus il est extensible en Python ! La configuration est très facile avec le fichiers json.
Néanmoins, j'ai envie de quelque chose de mieux, qui combine les avantages indéniables de vim avec un éditeur plus moderne comme Sublime.
Donc j'ai essayé emacs, trois fois. La première fois, j'ai juste essayé la version de base du système. Trop à apprendre, j'ai arrêté au bout de deux jours. Les raccourcis claviers ne sont vraiment pas intuitifs !
La seconde fois, je suis tombé sur un starter kit destiné aux sciences sociales, mais il était frustrant car il y avait des problèmes avec certains paquets. J'ai quand même bien appris. Je l'ai utilisé environ une semaine et je suis revenu à vim + sublime.
Et pour cette fois-ci, un collègue m'a recommandé spacemacs. Méfiant, j'ai enquêté autour de moi. La plupart des gens disaient genre nan, commence avec l'emacs de base, pas avec un starter kit. D'autres m'ont encouragé à essayer puisque ça marchait bien pour eux (certains sont des développeurs de plus de 20 ans d'expérience donc ça me paraît assez crédible).
J'ai essayé la version standard de spacemacs. Et bim ! Tout roulait, parfait. Mais je voulais quelques chose de plus simple, donc je suis passé à la version de base.
Après quelques jours de tests, encouragé et informé par la documentation et la communauté, j'ai eu plus de 500 lignes d'emacs lisp dans mon fichier de config, lignes que je comprends.
Ces trois jours ont été incroyablement éclairants pour moi: maintenant un ancien utilisateur de vim et sublime. J'ai déjà configuré un environnement de développement bien mieux que ce que j'avais sous vim ou sublime. Et je continue à explorer, en espérant donner un jour en retour à la communauté emacs.
Liens:
- http://spacemacs.org/
- des startes kits: http://wikemacs.org/wiki/Starter_Kits (spacemacs est axé sur l'édition modale. Si vous voulez un bon starter kit "normal", essayez Prelude)
- dev python: wiki, elpy

